NHANES prescription medication data hasn’t always been on my radar.
I’m not sure why this was so. NHANES is a well known national survey that began as a nutrition survey and quickly expanded to include a range of health variables, including results of a physician exam and laboratory tests. It is a national probability based sample, which means that one can generalize from the NHANES to the entire United States, and its methodologic standards are of the very highest. Perhaps the reason that I overlooked the prescription medication data is that there is so much data, and also, that NHANES was known primarily for nutrition data. Getting past my own blind spot, I decided to take a closer look at the prescription medication data collected in NHANES.
Here are some key points.
The survey
NHANES began in the 1960s and was conducted in waves, with a NHANES I, NHANES II and NHANES III. We love it so much that it became a permanent fixture. Since 1999 it has been conducted continuously in two-year cycles, and is now called NHANES continuous, or just NHANES. The US population is sampled over a two-year cycle and the data need to be analyzed using the full two-year sample. The sample is representative of the non-institutionalized, U.S. population and for example, does not include residents in nursing homes, or people in prison.
Sample size
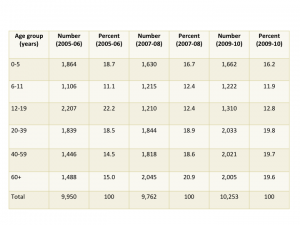
Sample size is critical to being able to estimate drug utilization. Unweighted sample sizes by age group are listed in the table below. While the numbers are large (every one of these people was interviewed in their homes), they may not be large enough for many purposes in pharmacoepidemiology. For those of us interested in pediatric medication use there were 4,194 people under 20 included in the sample. When stratified into age groups, the sample might not be large enough to study medications taken by small percentages (fewer than 1%) of children. The table below is taken from the NHANES website and shows unweighted sample sizes.
Table 2. Unweighted sample size and percents by age groups from NHANES 2005-06, 2007-08 and 2009-2010 for examined participants
NHANES prescription medication information
The medication information is collected during an in person interview in the participant’s home. During the interview, survey participants are asked if they have taken medications in the past 30 days for which they needed a prescription. Those who answer “yes” are asked to show the interviewer the medication containers of all the products used. For each medication reported, the interviewer enters the product’s complete name from the container into a computer. If no container is available, the interviewer asks the participant to verbally report the name of the medication. Participants are also asked how long they had been taking the medication and the main reason for use. This is in contrast to databases that rely on billing or claims data, or electronic health records. Documentation about the 2011-2012 data files containing prescription medication can be found here.
Using NHANES prescription medication data for pharmacoepidemiology
The pros and cons of using NHANES for pharmacoepidemiology are straight forward. On the pro side, NHANES may be the only probability based population sample in the United States with medication information. This alone makes it extremely valuable, and useful in conjunction with other types of data. The second strength, is that unlike health records, claims, or prescription data bases, the NHANES documents the presence of the medication in the patient’s home, demonstrating the the prescription was purchased and brought home. Along the continuum of measures, beginning with prescriptions written and prescriptions filled, documenting the prescription in the patient’s home brings us closer to understanding true exposures and levels of use. Another positive that needs to be explored is the availability of information from the physical exam and laboratory tests for the person using a given prescription.
On the con side, the sample sizes may be too small to provide stable estimates of many medications, especially if one wishes to study use within a sub-group. In terms of bias, my first thought is that this method of estimating use will result in underestimates of use, with people forgetting, omitting or otherwise not reporting their medication use to an interviewer. Misclassification in the other direction might occur when a person has filled a prescription and shows the prescription to the interviewer, but does not take the prescription. This latter source of bias would lead to an over-estimate of use but would also effect each of the other types of measures of prescription medication use (prescriptions written or prescriptions filled also over-estimate the numbers of people actually using the medication.
Recent publications using NHANES prescription medication data
A quick search turns up several publication analyzing prescription medication data in NHANES, but not as many as one might expect. An interesting use of the data is that of Bateman and colleagues (2012) focusing on a group with a risk factor, hypertension, and describing the medication use within that group. This usage may have applications for people working in health economics and outcomes research.
- Farina EK, Austin KG, Lieberman HR, “Concomitant Dietary Supplement and Prescription Medication Use Is Prevalent among US Adults with Doctor-Informed Medical Conditions” J Acad Nutr Diet 2014 Apr 4 S2212-2672(14)
- Bertisch SM, Herzig SJ, Winkelman JW, Buettner C, “National use of prescription medications for insomnia: NHANES 1999-2010” Sleep. 2014 Feb 1;37(2):343-9
- Chong Y, Fryer CD, Gu Q, “Prescription sleep aid use among adults: United States, 2005-2010” NCHS Data Brief. 2013 Aug;(127):1-8
- Gu Q, Burt VL, Dillon CF, Yoon S, “Trends in antihypertensive medication use and blood pressure control among United States adults with hypertension: the National Health And Nutrition Examination Survey, 2001 to 2010” Circulation. 2013 Jun 18;127(24)
- Bateman BT, Shaw KM, Kuklina EV, Callaghan WM, Seely EW, Hernandez-Diaz S, “Hypertension in women of reproductive age in the United States: NHANES 1999-2008” PLoS One. 2012;7(4):e36171
- Kinjo M, Setoguchi S, Solomon DH, “Antihistamine therapy and bone mineral density: analysis in a population-based US sample” Am J Med. 2008 Dec;121(12):1085-91